2nd Offline Reinforcement Learning Workshop
Neural Information Processing Systems (NeurIPS)
December 14, 2021
@OfflineRL · #OFFLINERL
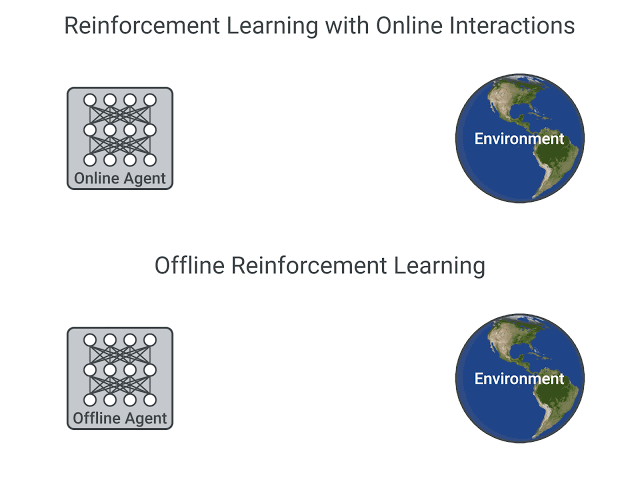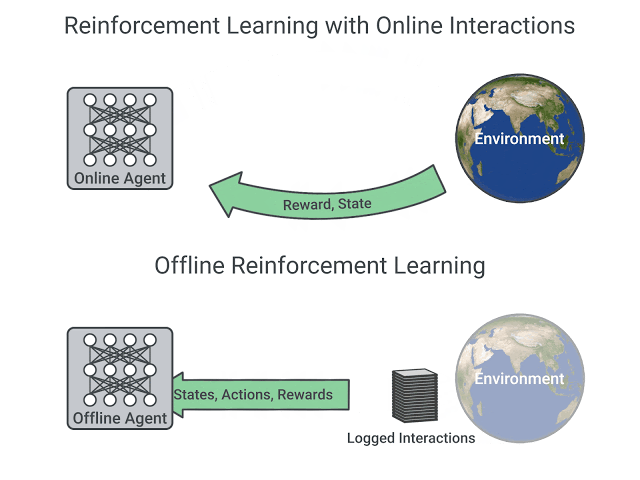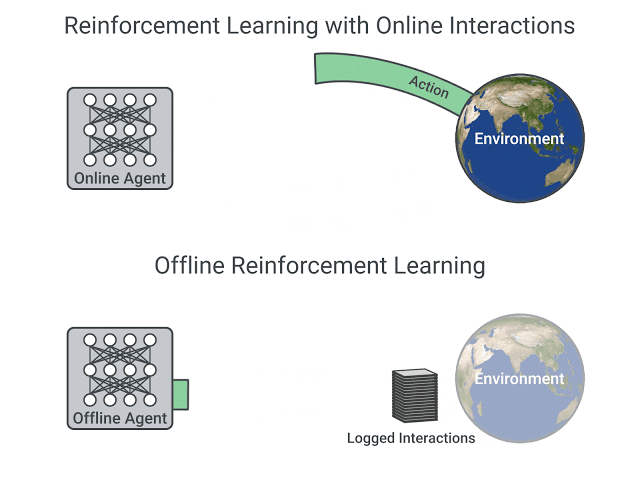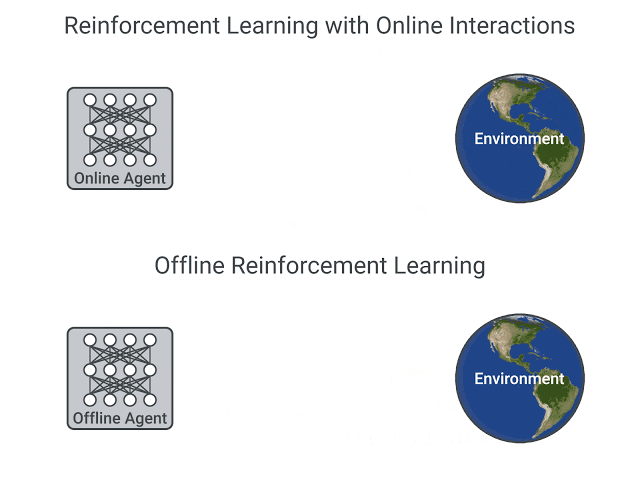
Offline reinforcement learning (RL) is a re-emerging area of study that aims to learn behaviors using only logged data, such as data from previous experiments or human demonstrations, without further environment interaction. It has the potential to make tremendous progress in a number of real-world decision-making problems where active data collection is expensive (e.g., in robotics, drug discovery, dialogue generation, recommendation systems) or unsafe/dangerous (e.g., healthcare, autonomous driving, or education). Such a paradigm promises to resolve a key challenge to bringing reinforcement learning algorithms out of constrained lab settings to the real world.
The 1st offline RL workshop, held at NeurIPS 2020, focused on and led to algorithmic development in offline RL and garnered wide attention. This year, we propose to shift the focus from algorithm design to bridging the gap between offline RL research and real-world offline RL. Our aim is to create a space for discussion between researchers and practitioners on topics of importance for enabling offline RL methods in the real-world. We will encourage discussions and contributions around (but not limited to) the following topics that are important in the context of enabling real-world applications of offline RL methods:
- Offline RL using datasets unrelated or loosely-related to the task of interest
- Real-world domains and benchmarks for offline RL
- Cross-validation, model selection and hyperparameter tuning in offline settings
- Accelerating lifelong and continual learning via offline RL
- Novel application domains for offline RL, e.g., black-box optimization.
- Beyond pessimistic offline RL algorithms: generalization and uncertainty quantification
- Optimization, stability and learning dynamics of offline RL algorithms
The submission deadline is October 6, 2021 (Anywhere on Earth). Please refer to the submission page for more details.
Program Committee
- Adam R Villaflor
- Alex Irpan
- Alex Lewandowski
- Anurag Ajay
- Ben London
- Biwei Huang
- Bo Dai
- Brandon Trabucco
- Canmanie T. Ponnambalam
- Chaochao Lu
- Cosmin Paduraru
- Daniel Seita
- David Krueger
- Dibya Ghosh
- Francesco Faccio
- Hadi Nekoei
- Homer R Walke
- Ilya Kostrikov
- Jacob Buckman
- Jiawei Huang
- Joey Hong
- Karush Suri
- Kevin Lu
- Konrad Zolna
- Ksenia Konyushova
- Luckeciano C Melo
- Masatoshi Uehara
- Ming Yin
- Oleh Rybkin
- Qiang He
- Rafael Rafailov
- Rahul Siripurapu
- Romina Abachi
- Ruosong Wang
- Kamyar Ghasemipour
- Shangtong Zhang
- Stephen Tian
- Taylor W Killian
- Tengyang Xie
- Thanh Nguyen-Tang
- Thomas L Paine
- Tianhe Yu
- Tianyuan Jin
- Yanan Wang
- Yevgen Chebotar
- Yi Su
- Yijie Guo
- Yue Wu
- Yuta Saito
- Yuwei Fu
Organizers






To contact the organizers, please send an email to offline-rl-neurips@google.com.
Thanks to Jessica Hamrick for allowing us to borrow this template.